
競馬データを集めて、機械学習をし、予想に役立てる。
はい、毎週の記事だけではなく、たまにはみなさんと一緒に競馬予想の勉強をしたいと思います。さて、今回はレースを楽しむために予想の一部に機械学習を取り入れてみようというものです。
考え方
機械学習の進め方は下記の流れになります。機械学習とは簡単に言うとデータから知識を引き出すことですね。
1.データを集める。
ここで集めるデータは過去のレース結果となりますが、集め方は予想対象レースの条件と同じデータを競馬サイトからスクレイピングすることになります。レース条件は芝・ダート、距離、競馬場、クラス(重賞、OP、3勝クラスなど)ですね。細かいところはプログラムを紹介しながら説明していきます。プログラムはPythonです。
2.集めたデータをもとに学習モデルを作成する。
学習モデルを作成するにあたり、機械学習では様々なアルゴリズムが用意されています。ここでは競馬予想において比較的よく使用されているランダムフォレストを使用しています。
3.予想するレースの出馬データを準備する。
学習モデルを作成したら、実際に予想するレースの出馬表データを準備します。しっかりと学習するために出馬表データを学習モデルがきちんと読み込める形に整理します。これをデータの前処理といいます。例えば、出走取消などで空欄になった部分を適切に処理します。
4.予想する。
前処理した出馬表データを、作成した学習モデルに入力(放り込み)し、予想させます。
プログラムファイル
プログラムは下記を準備しています。
- RaceIDリスト(過去のレース結果のRaceIDリスト)
- Traning_RF(ランダムフォレストを使用して学習モデルを作成)
- Shutuba_Pre(予想するレースの出馬データを作成)
- Test_RF(実際の予想プログラム)
では、順番に見ていきましょう。
RaceIDリスト
データを集める対象となる過去のレース結果はnetkeibaのサイトからスクレイピングします。netkeibaが公開しているレース結果のURLを見るとわかりますが、URLは2024年のダービーの場合、”https://db.netkeiba.com/race/202405021211/”となっています。最後の数字の部分が、年(2024)、開催場(05:東京)、第○回(02:第2回)、○日目(12:12日目)、レース番号(11:第11レース)です。この数字をRaceIDと呼びます。予想したいレースのレース条件に合わせてRaceIDを抽出します。例として東京ダート1400mの場合は下記のようなリストとなります。

この例の場合、スクレイピングしたレース数は700レース程度で、2016年~2023年までのレースとしました。2024年分はあとで予想で使用するため、学習用のRaceIDには用いていません。新馬戦は過去データが無いので除いています。
Traning_RF
学習モデルを作成するプログラムです。プログラム構成は以下の流れです。
- RaceIDを指定して、そのURLから必要な情報をスクレイピングする関数。スクレイピングするときはサーバに迷惑がかからないようにプログラム途中に待ち時間を挟むと良いですね。

- RaceIDリストを順番に指定し、日付、horse_id、jokey_idなどのレース結果リストを作成する(①)。

- horse_idリストをもとに、馬毎のレース成績(着順平均、賞金平均、着差平均)を作成する(②)。①、②を結合して、学習用リストを作成する。

- 学習アルゴリズムであるランダムフォレストで学習させ、モデルを作成する。予想については馬券に絡む1着~3着に入る可能性のある馬を予想します。

- 作成したモデルを保存しておきます。あとで、予想をするときのプログラム(Test_RF)内でこのファイルを呼び出します。

Shutuba_Pre
- 予想対象レースを選び、予想用のデータを準備します。

- 学習モデルを作成したときと同じ特徴量を追加していきます。

Test_RF
- 出馬データを最後に整理して、前処理したデータをCSV出力します。

- Traning_RFで保存した学習モデルを呼び出します。

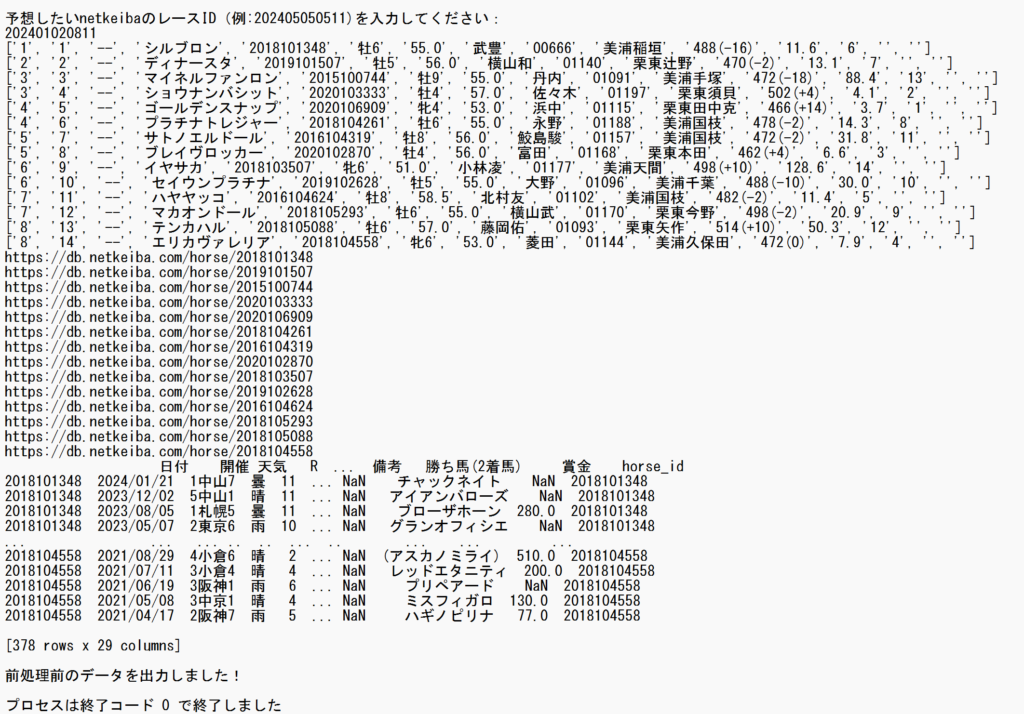
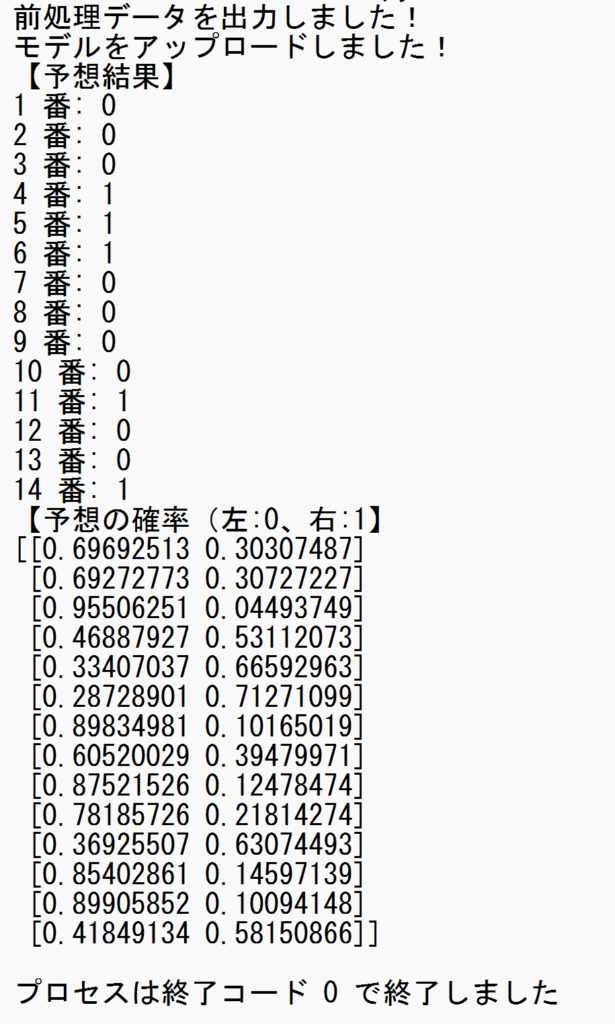
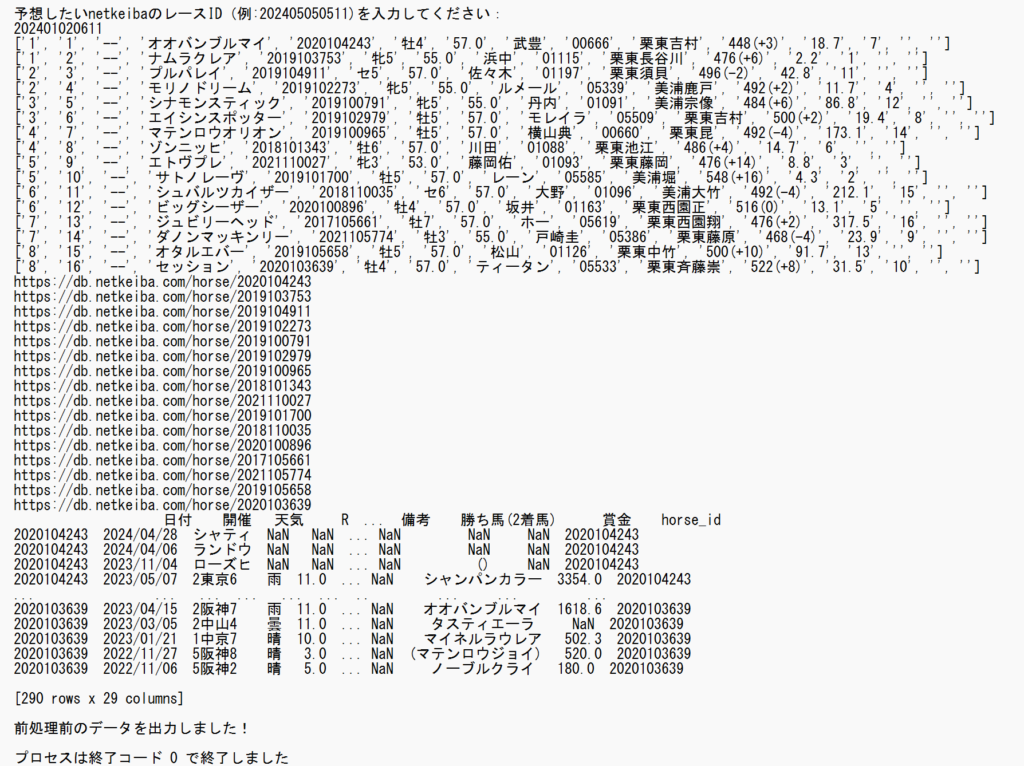
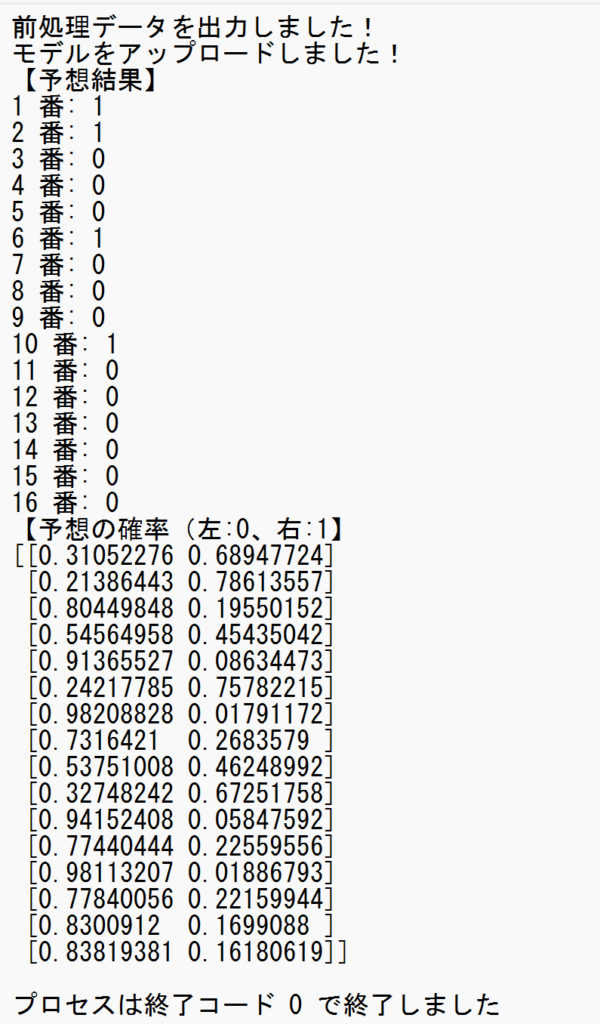
- 各馬の予想結果を表示します。3着内に入る確率が高いものが「1」、その他は「0」で表示します。

実際の予想
最初がShutuba_Preの実行結果、次がTest_RFの実行結果です。
2024年9月1日 2回札幌8日目 タイランドC
【結果】1着:4番、2着:5番、3着:11番!!!
2024年8月25日 2回札幌6日目 キーンランドカップ(GIII)
【結果】1着:10番、2着:6番、3着:1番!!!
まとめ
競馬予想に機械学習を用いる手法を解説してきました。この記事で紹介した基本プログラムを使用して、様々なレース条件での学習モデルを複数作成していけば、予想したいレースに活用できますね!


コメント